Blog
What is bioinformatics?
March 31, 2017
Bioinformatics is a huge field with many definitions. This video discusses a broader definition of bioinformatics based on the intersection of biology, computer science, and math/statistics. I also break research in the field up into 3 categories based on the primary methods employed by scientists to do their research.
Here’s what I tell non-scientists that I do: “I use computers to analyze biological data.”
Just to be sure, I went to the almighty Wikipedia to check that I wasn’t crazy, and Wikipedia agrees. “Bioinformatics is an interdisciplinary field that develops methods and software tools for understanding biological data.”
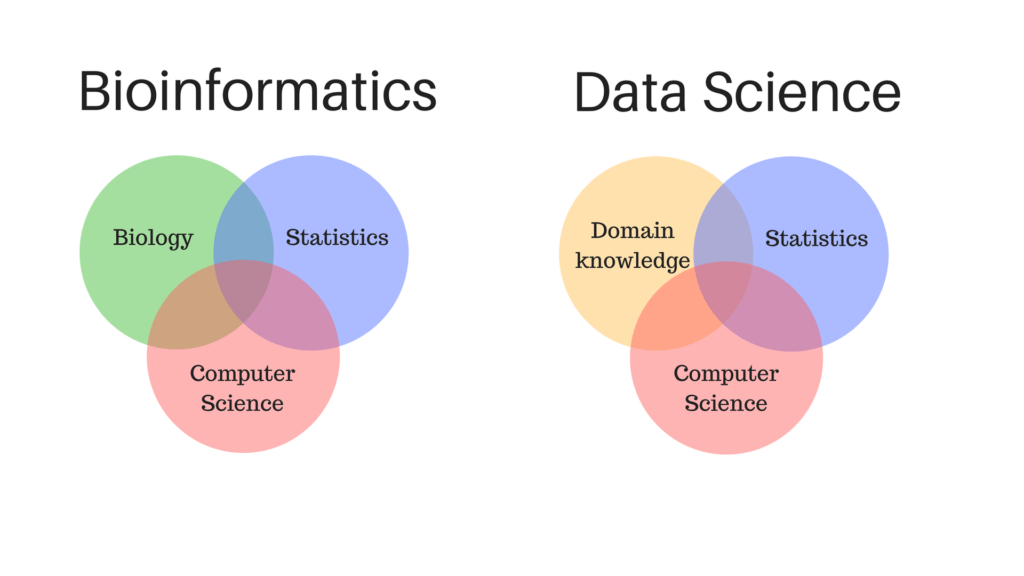
People in bioinformatics also like to make a big deal about the Venn diagram where Biology, meets Computer Science, meets Statistics.
Notice that this looks an awful lot like the Venn diagram that Data scientists make, where Computer Science, meets Statistics, meets “Domain knowledge.”
So maybe if we want to impress our friends and improve our earning potential, we should start calling ourselves biological data scientists. But depending on what we do exactly, the title could also be “bioinformatics software engineer,” or something completely different.
I have heard multiple people debate the difference between bioinformatics and computational biology, and they don’t usually agree on what the difference is.
A more useful distinction, as far as I see it, is between these 3 major approaches to doing bioinformatics research:
- Data analysis: Going from raw data, to clean data, to statistical and visual interpretations of the results)
- Bioinformatics software development: Developing software to do bioinformatics analysis, big enough software products to publish as independent methods papers and to be used by other scientists.
- Modeling: Performing simulations and writing equations to represent biological systems.
One of the things that makes bioinformatics interesting is the convergence of people from different fields. They bring with them their backgrounds and their inclinations towards different ways of thinking about biological problems.
- Data analysis is the most natural starting point for biologists and involves the most domain expertise because it specifically involves interpreting the data. The ability to detect oddities or interesting patterns in the data can heavily depend on your knowledge of the biological system the data comes from.
- Bioinformatics software development is an approach to bioinformatics that I see computer scientists naturally take on. They may also do data analysis, but will have a hard time resisting building real software products. The software they develop can take many forms, from command-line tools to web applications.
- Modeling is very fashionable with physicists and mathematicians. You can tell their work apart by the fact that it’s full of equations and written in LateX.
I’ll give an example for each of these from my own experience:
- Data analysis of long-read sequencing data in SKBR3, running command-line tools like aligners and variant-callers, integrating data of different types, and interpreting the results using summary statistics and plotting.
- Bioinformatics software development includes command-line tools and web applications, which I made several of to satisfy the demands of the SKBR3 project. My application SplitThreader (github link) puts an interactive, visualization-based web interface around a set of command-line tools for interpreting copy number profiles and long-range variant data.
- Modeling I didn’t do heavily in my PhD, but I had an undergraduate research project with a math professor in college where we used a network to simulate flu spread on a college campus.
Feel free to discuss in the comment section under the video on YouTube.