Scalable software
for complex biology.
We help our clients turn large, fragmented genomics data into actionable biological signal.
Our expertise in action
We build power tools
that are a joy to use
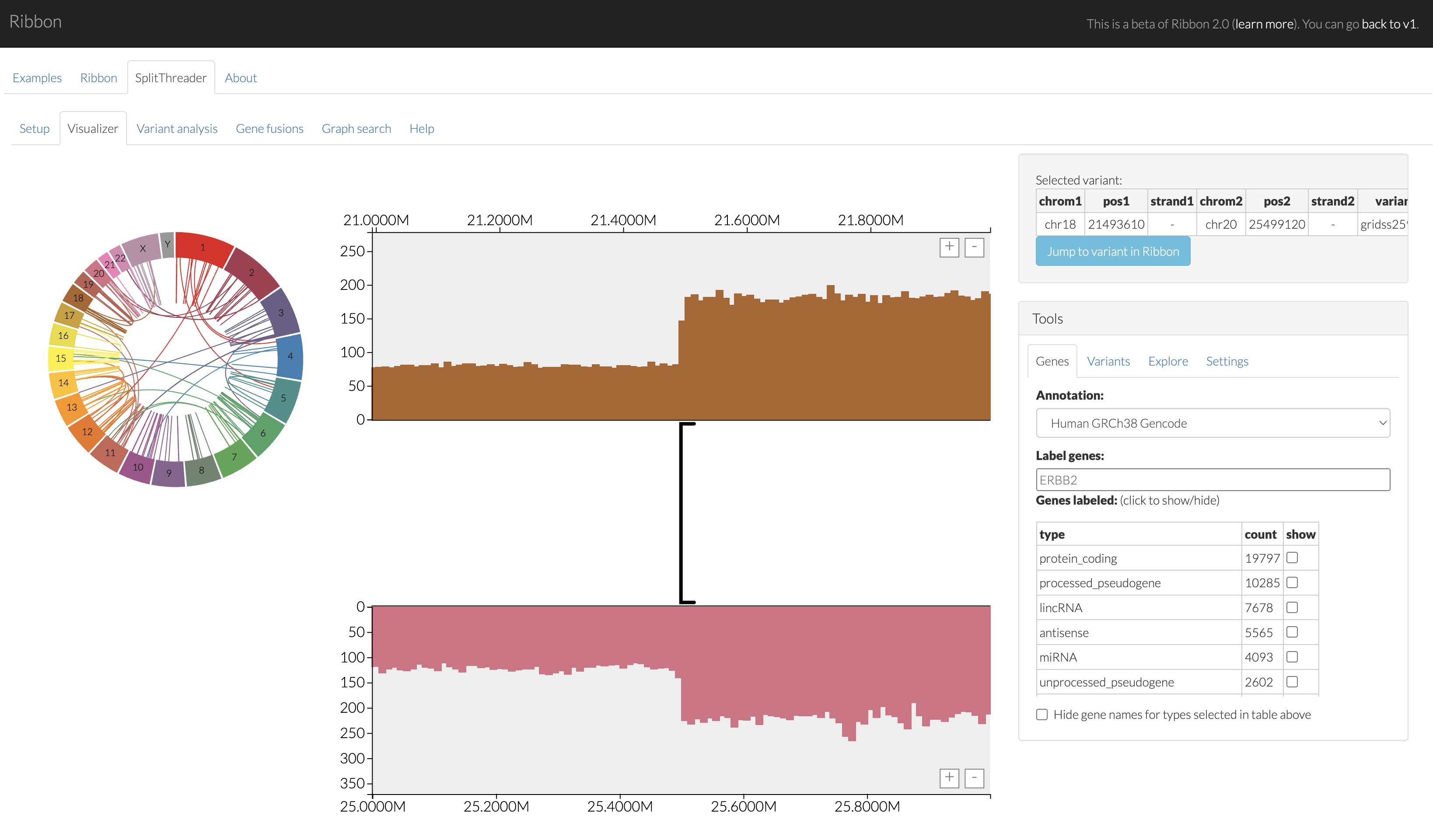
Biological data can be full of insights, but only if you can actually find them. We create interactive, high-performance visualization tools that make complex genomic data intuitive.

We build cloud infrastructure
at genomics scale
Inspecting genomic data shouldn't require waiting for large downloads or spinning up heavy cloud instances. We create high-performance, browser-native tools that make cloud datasets more accessible.

We build interactive
compute environments
Using biowasm, our WebAssembly-powered ecosystem, scientists can securely run bioinformatics tools in a web app for on-the-fly compute. We can integrate these environments into your internal tools to let your scientists inspect data outside production pipelines, without wasting time installing bioinformatics tools.

We build custom data viz
for new biology
When off-the-shelf tools aren't enough for new biological data types, we engineer custom visualization tools to help you make sense of those new modalities.
Leading the technical conversation
Over 48,000 scientists are subscribed to our YouTube channel, where we share our insights, and interview domain experts to help us understand the future of our field.



Ready to accelerate R&D velocity?
We eliminate the software bottlenecks holding back your science.
Schedule a meetingPrefer email? [email protected]